(EuroSys2024) Warming Serverless ML Inference via Inter-function Model Transformation
Serverless ML inference is an emerging cloud computing paradigm for low-cost, easy-to-manage inference services. In serverless ML inference, each call is executed in a container; however, the cold start of containers results in long inference delays. Unfortunately, most existing works do not work well because they still need to load models into containers from scratch, which is the bottleneck based on our observations. Therefore, we propose a low-latency serverless ML inference system called Optimus via a new container management scheme.
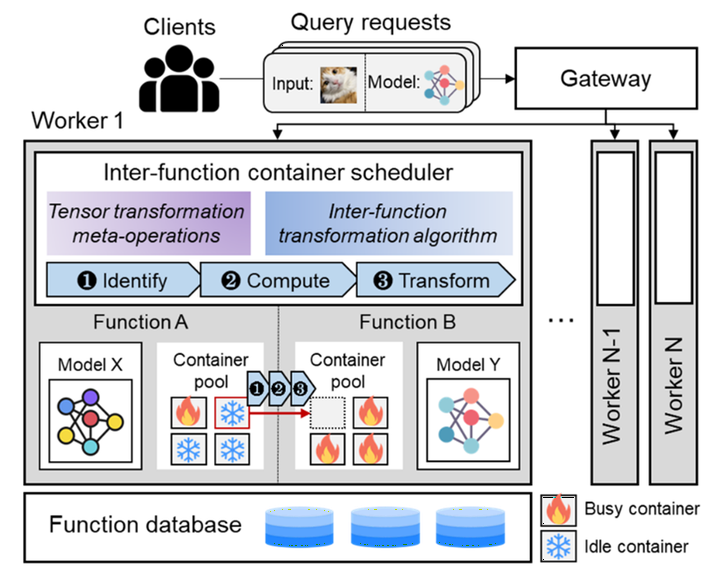
Prototype Overview
Optimus API and communication between clients and the gateway are implemented in REST API format. Clients can invoke an inference procedure by sending an HTTP request containing the model name and input data. Optimus stores the trained models in a Docker volume that is attached directly to each container created by the system. Models are deployed to the Docker volume in HDF format. Model structure information and model-to-model transformation planing are stored with the models in JSON format. On the host machine, a gateway service runs as the container manager. It uses the Docker SDK for Python to create, run, and remove containers in the local Docker environment. It also runs a Flask HTTP server that accepts client requests and sends them to containers.