Introduction of "Cloud-Edge Collaborative Large Models"
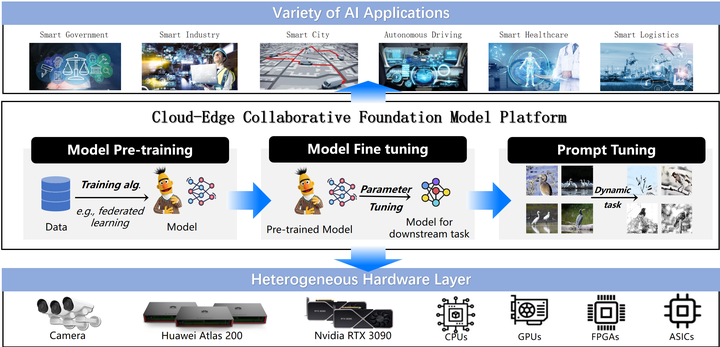
In pursuit of building open, intelligent, and efficient AI large models, we aim to address the challenges posed by diverse data and resources distributed across edge devices, which can significantly impact the performance and scalability of large models.
To achieve this goal, our research plan encompasses three critical aspects:
Model Pre-training: By leveraging the extensive computational resources available in the cloud and edge environment, we will pre-train large models on vast datasets. This pre-training phase is crucial for developing robust and generalized models that can handle a wide range of tasks and scenarios. Details
Model Fine-Tuning: Once pre-trained, these models will be fine-tuned on more specific datasets and tasks, utilizing both cloud and edge resources. This fine-tuning process ensures that the models are tailored to the unique requirements and constraints of edge devices, thereby enhancing their performance and efficiency in real-world applications. Details
Prompt Tuning: To further optimize the models for specific tasks and improve their responsiveness, we will employ prompt tuning techniques. This involves adjusting the models' inputs and configurations dynamically based on real-time data and user interactions, ensuring that they deliver accurate and contextually relevant outputs. Details
Through this comprehensive approach, the research on Cloud-Edge Collaborative Large Models aims to create AI systems that are not only powerful and versatile but also capable of operating efficiently across diverse and distributed environments.